캐싱은 성능 향상, DB 트래픽 부하 감소 이로인한 비용 절감등의 이유로 많은 시스템에서 사용된다.
어떠한 전략을 선택하느냐에 따라 데이터 정합성 문제, 조회 성능이 달라질 수 있기 때문에 전략을 고려해야한다.
캐시 읽기 전략
Cache-Aside

캐시를 옆에 두고 필요할 때만 데이터를 캐시에 로드하는 전략이다.
초기 조회 시 DB에서 데이터를 호출 해야 하므로 단건 호출 빈도가 높은 서비스보다는 반복적으로 데이터를 조회하는 서비스에 적합하다.
- Look Aside, Lazy Loading 전략이라고도 불린다.
- 가장 일반적으로 사용되는 캐싱 접근 방식이다.
- Memcached 와 Redis가 널리 사용된다.
- 캐시에 붙어있던 connection이 많다면, 캐시가 다운된 순간 많은 요청이 DB로 몰려서 부하가 발생한다.
- 웹 서버는 캐시, DB 모두 직접 통신하며 캐시와 DB 사이에는 연결이 없고 캐시와 DB에 대한 모든 작업은 웹 서버에서 처리하기 때문에 캐시 저장소가 다운되어도 데이터를 제공할 수 있다.
Read-Through
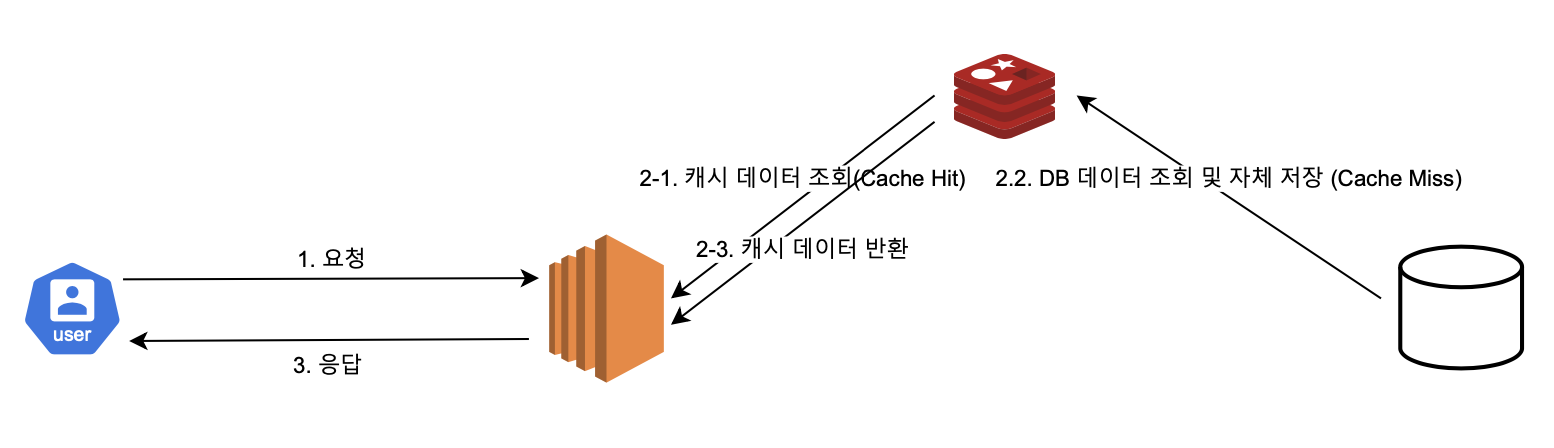
캐시와 DB가 일렬로 배치된다. 이로인해 Cache-Aside와 달리 캐시 저장소에서만 데이터를 읽어오는 전략이다.
캐시 저장소에서만 데이터를 읽어오기 때문에 당연히 캐시 저장소가 다운되면 데이터를 제공할 수 없다.
캐시 저장소 다운에 대비하여 서버를 Replication 하거나 Cluster로 구성하여 가용성을 확보해야한다.
데이터 동기화를 애플리케이션이 하지 않고 캐시에서 DB 데이터를 조회하여 자체 업데이트하기 때문에 데이터 정합성 문제를 해결할 수 있다.
캐시 쓰기 전략
Write-Through

DB에 데이터를 저장할때 먼저 캐시에 데이터를 추가하거나 업데이트하고 DB 데이터를 저장하며 그 작업은 Read-Through와 마찬가지로 캐시에서 한다.
이로 인해 캐시 데이터는 항상 최신 정보를 가지게 되며 데이터 정합성 문제가 해결된다.
단, 재사용되지 않는 데이터도 무조건 캐시에 저장되기 때문에 적절한 TTL 설정이 필요하며,
빈번한 생성, 수정 서비스에는 성능 이슈가 있을 수 있다.
Write-Back

Write-Through와 비슷해 보이지만 데이터를 저장할때 DB에 바로 저장하지않고 일정 주기로 배치 작업을 통해 DB에 반영한다는 차이가 있으며 쓰기 쿼리를 배치로 작업하기 때문에 성능을 높일 수 있다.
그 외 특징은 Write-Through와 똑같으며, Write-Back은 쓰기 작업이 더 빈번하면서 조회시 성능이 요구되는 서비스에 적합하다.
Write Behind 패턴 이라고도 불린다.
Write-Around

Write Through보다 훨씬 빠르다.
모든 데이터는 DB에 저장하고 Cache miss가 발생하는 경우에만 캐시에도 데이터를 저장한다.
그러므로 데이터 정합성을 보장하지 않는다.
DB에 데이터가 수정되면 캐시와 데이터가 다를 수 밖에 없으니 캐시 데이터 또한 삭제하거나 변경, 짧은 TTL 설정을 해야한다.
자주 사용되는 캐시 읽기 + 쓰기 전략
Look Aside + Write Around

가장 많이 사용된다.
모든 데이터는 DB에 저장하면서 Cache miss가 발생하는 경우에만 애플리케이션이 캐시에도 데이터를 저장한다.
Read Through +Write Around

모든 데이터는 DB에 저장하고, 데이터 조회시 캐시에서 DB 데이터를 조회하기 때문에 이론상 정합성이 유지된다.
하지만 DB 데이터를 수정할시 캐시에서 cache Miss를 해줄수 있는 정책이 필요하다.
캐시에 기존 데이터가 있기 때문에 캐시 HIT가 되면 정합성 보장이 안된다.
Read Through + Write Through

DB에 데이터를 저장할때 먼저 캐시에 데이터를 추가하거나 업데이트하기 때문에 조회시 최신 데이터를 보장하며 그 데이터를 DB에도 저장하기 때문에 DB와 캐시간의 정합성이 보장된다.
AWS의 DynamoDB Accelerator(DAX) 도 이 전략을 사용한다.

심화
Thundering Herd

서버 자원에 동시에 접근하려는 요청들이 몰려드는 현상을 포괄적으로 설명한다.
여러가지 예시가 있다.
서버 재시작 후 동시에 다수의 요청이 몰리거나,
lock을 기다리는 여러 스레드들이 동시에 깨어나 접근할때나,
캐시와 관련된 Thundering Herd 문제 Cache Stampede도있다.
Cache Stampede
TTL이 만료된 후, 다수의 요청이 캐시를 건너뛰고 DB로 몰리는 현상이다.
문제 상황 예시
캐싱 데이터의 TTL이 만료되고 동시에 많은 요청이 들어왔다고 가정한다.
Cache Miss가 발생 하였고 이로 인해 RDB에 동시에 조회를 요청하여 데이터베이스에 높은 부하가 발생되었다.
이를 예방하기 위해
캐시 조회 자체에 lock을 잡아두거나 (당연히 조회마다 lock이 걸리니 성능은 좋지 않을것이다.)
분산 락을 사용해서 캐시 미스가 발생했을 때 락을 설정하고 캐싱한 후에 락을 해제함으로써, 단 한 번의 쓰기 작업만 허용한다거나
(락을 통해 1번의 쓰기만 발생하기 때문에 DB에 높은 부하가 발생되지 않는다.
자세한 내용 https://velog.io/@gkdbssla97/Thundering-Herd-Problem을-마주쳤다 참고)
주기마다 Cache Warming(DB에서 캐시로 데이터를 미리 추가하는 작업)을 한다거나
캐시가 만료되기전에 미리 로딩하는 방법(Preloading and warming up the cache),
TTL 만료 시간을 분산하여(동시에 대량의 캐시가 만료되지 못하게 적절히 랜덤하게 저장)하는 방법이 있다.
'메모하는 습관 > 백엔드 스프링' 카테고리의 다른 글
| 실시간 통신 기술 (2) | 2024.12.09 |
|---|---|
| Redis 캐시 적용 해보기 (0) | 2024.09.11 |
| 낙관적락이 롤백되는 이유 (0) | 2024.09.11 |
| Mybatis 동작 원리 (0) | 2024.08.28 |
| SHA-256 핵심, 요약, java 구현, 결론 (0) | 2024.08.28 |